Diabetes mellitus (DM) has been found in humans for centuries. Over the years, the classification and categorization of its spectrum has undergone many iterations, mirroring science’s ever-developing understanding of this complex disease.
As today’s medical and technological advances continue to be utilized and applied to DM, a newer and even more complex framework for the disease is emerging, which may help us further our understanding of it. This article explores the most recent classification update and some of the newer thinking emerging about DM.
Why is Classification Needed?
Classification is a tool used in scientific disciplines, partly as a naming system and partly to organize existing knowledge. In medicine, classification systems for diseases are useful, as they not only include causes, underlying mechanisms, progression and natural history, they also contribute to the development of new treatment approaches.1
The goal of disease classification is to standardize diagnoses. This, in turn, can enable a better understanding of a disease’s epidemiology, even across geographic regions. Standardized classification can also promote ongoing discussion and cohesive research into the what and how of diseases. Grouping together disease subsets that share similar prognoses and responses to specific treatment plans may guide clinical treatment approaches.
Risk Industry Implications
Classification of any disease changes over time as newer and fuller information and knowledge emerge. We find ourselves in an age of great information expansion, made possible by technological tools that include large-scale genome studies and the ability to rapidly process and share large quantities of data from around the world at speeds unimaginable only a decade ago. For DM, these advances, which are improving the understanding of clinical risk and disease progression prediction, and enabling the discovery of specific disease-targeted treatments, may significantly enhance risk estimation, stratification and underwriting. These advances may also present the possibility of a personalized approach to DM risk prediction.
DM Classification: Over the Years
The history of DM’s classification reflects the conundrum and wonder of the phenomenon of raised blood glucose (hyperglycemia) as well as the struggles and triumphs experienced by people living with the disease and by the medical fraternity members committed to their care.
As a species, we humans have been living with diabetes for a very long time. A possible description of Type 1 DM (T1DM) was documented by Egyptians about three millennia ago, highlighting the symptoms of emaciation, thirst and frequent urination.3
As early as the fifth century A.D., two forms of DM had been observed and described: one occurring in older, fatter people, and the other in younger, thinner people, who had shorter lifespans.4
The need for classification of DM types was acknowledged by the mid to late 19th century, but a formal classification system was not established until 1965. In that year, the World Health Organization (WHO) first published its DM classification system. The system used four age-band categories to organize children, teens and young adults, young to middle-aged adults and the elderly with DM. Other forms of Tdiabetes that did not conform to the age-band system, such as brittle, insulin-resistant, gestational, pancreatic, endocrine and iatrogenic, were listed as well.5
The 1980 classification update, a consensus proposed by the National Diabetes Data Group (NDDG) and endorsed by both the WHO Expert Committee on Diabetes and the WHO Study Group on DM, is the foundation upon which subsequent updates have been built. This system was the first to recognize the Type 1 and Type 2 classes and included a category for gestational diabetes as well as an “others” category. It received global acceptance and adoption.6
The 1999 WHO classification update introduced subtype categories for T1DM and T2DM that explained the mechanisms causing the different types.7 T1DM was divided into autoimmune and idiopathic subtypes, while T2DM was divided into predominantly insulin-resistant and predominantly insulin-secretory defects subtypes. Gestational DM and “other” types made up the remaining DM classifications. A clear attempt was also made to show the progressive nature of DM by listing the five clinical states within each DM type:
- Normal glucose tolerance
- Impaired glucose regulation
- Insulin not required for control
- Insulin required for control
- Insulin required for survival
This classification framework showed DM’s heterogeneity in genesis and clinical presentation, and a nuanced appreciation that the progression of metabolic dysfunction in DM may be reversible.
Over the next two decades, debates emerged with focus on defining hyperglycemia levels for diagnosing DM, gestational diabetes and intermediate hyperglycemia. However, the basic approach to classifying T1DM, T2DM and gestational diabetes remained largely the same.
The 2019 WHO Classification Update
The newest revision to WHO’s DM classification system, released in 2019, is its first revision in 20 years. In the executive summary, the revision committee acknowledged that knowledge gaps remain in the causes and pathophysiology of DM, and that classification is further confounded by the rapid changes in DM epidemiology among the young. Consequently, the subtype categories under both T1DM and T2DM have been removed, and a “hybrid” category introduced to describe atypical cases with features of both DM types.
In addition, the “other” category—now called “other specific types”—has grown significantly. This is an expected outcome of the growing knowledge of the relevant genetics, molecular bases and metabolic processes in DM. Table 1 provides a brief overview.1
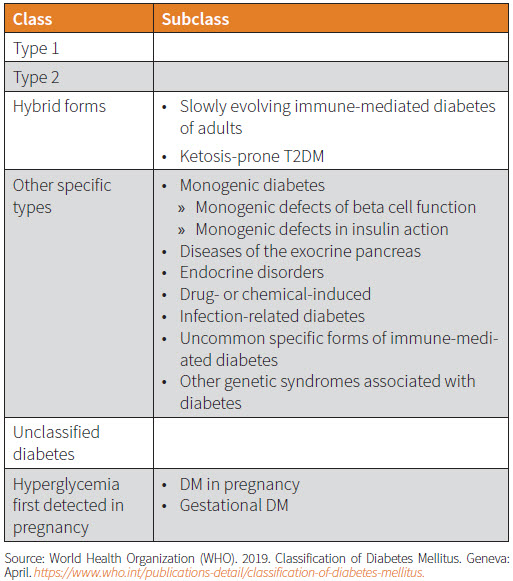
This revision reflects several important elements. It acknowledges that DM phenotypes can vary significantly. Newer tests and analyses have enabled the identification of more DM subtypes.
The current approach for DM classification may also not be sufficiently timeproof and could become outdated. A more fundamental approach to DM’s diagnostic model and classification might be needed.
Two novel approaches are emerging, which are still being examined, studied and validated by peer groups: the palette model and DM clusters.
The Palette Model
In genome-wide association studies (GWAS) in which the genetic characteristics of DM populations were studied, many genetic variants have been identified as having causative potential for DM. The number of variants identified so far is in the several hundreds and rising, but only a handful of these have been determined to have significant causative effect when it comes to DM. Most have only weak effects on its manifestation but may contribute toward collective risk if occurring together.
In most cases, DM results not from failure of one single biological process but from the incremental impact of dysfunctions in multiple processes. These errors produce an accumulation of disordered systems over variable time periods culminating in hyperglycemia, except in cases where a highly potent genetic mutation is present that could, in isolation, cause abnormal glucose metabolism. Monogenetic diabetes is just such a case.

At the Oxford Centre for Diabetes, Endocrinology and Metabolism, Mark I. McCarthy and his team have been doing extensive research into the genetics of DM. Using their findings and knowledge from other genetic research, this team has developed the palette model as an explanation for the full spectrum of DM as a continuum of disorders.
The model reflects the genetic basis of DM’s disease physiology. It proposes that each person has a unique genetic makeup with its specific susceptibility to (or protection from) developing DM. The genetic susceptibility is determined by the accumulation of at-risk genetic variants that govern underlying metabolic processes contributing toward DM development. Multi-factorial influences further act on this risk over time, which may result in the variable clinical manifestation of DM.
Examples of metabolic processes involved may include obesity development, insulin production, insulin sensitivity, glucagon production and pancreatic cell autoimmunity. These processes would be associated with various identified genetic variants in the GWAS.
This model provides an alternative paradigm for understanding DM: its heterogeneity, the mechanisms that can lead to it, its onset and its clinical outcomes. It can represent overt DM in newborns to lateonset mild DM in the elderly and has been validated by empirical studies that support the approach.8
McCarthy and his team are developing a polygenic risk score that might improve the ability to predict an individual’s risk of developing DM. This could help find individuals at risk for DM earlier so that specific dysfunctions can be targeted for reversal— an improvement that could have the potential to translate to overall disease burden reduction.9
Although genetic testing might turn out to have some applicability in DM, genetic studies are still primarily a research tool, not yet available to the wider clinical community. Also, the role of genetics as an explanation for the presentation of a multifactorial disorder such as DM is still limited. Non-genetic internal and external factors play significant roles in the manifestation of diabetes.
Ultimately, the palette model may provide a useful conceptual framework to explain the mechanism of DM, but its utility value to the broader clinical community is limited at this time.
DM Clusters
A team led by Emma Ahlqvist of Lund University in Sweden is looking at existing clinical and biochemical biomarkers as a way to classify DM’s many manifestations. Some of the biomarkers may be examples of process outcomes cited in the palette model. Using data analysis, this team hopes to improve the mapping of the clinical course of diabetes from diagnosis to end-organ damage.
Ahlqvist’s team retrospectively analyzed the data of 15,000 patient records from Swedish and Finnish registries with a follow- up period of eight years and from the analysis identified five diabetes subtype clusters. The biometric parameters used included insulin resistance, beta cell function, auto-antibodies against islet cells, A1c levels, age at diagnosis and body mass index (BMI). Genetic information was not used, as the study only looked at clinical and biochemical biomarkers already available.10
A pattern was identified from one database and then validated against other available datasets. Five clusters of diabetes types emerged, with each cluster identified according to certain characteristics. This is illustrated in Table 2.
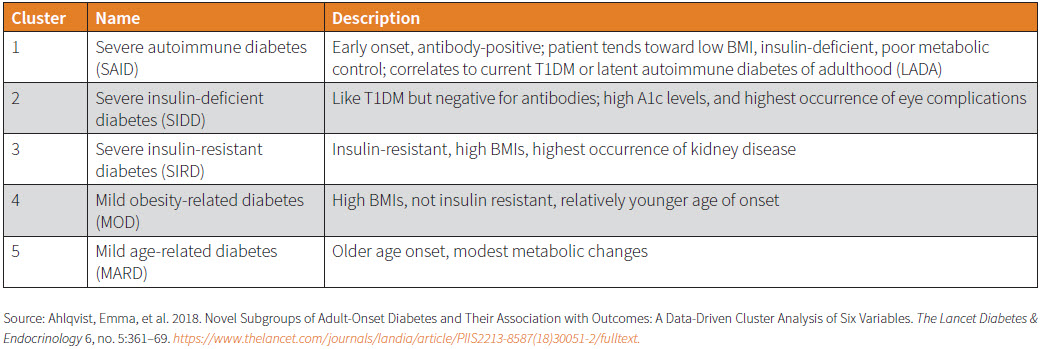
This clustering system demonstrates the heterogeneity in DM’s clinical presentation. Clusters 3, 4 and 5, for example, would have been classified as T2DM in the WHO 2019 system. This classification also predicted certain clinical outcomes for the different types: One cluster was more prone to developing eye complications while another to developing kidney disease.11
Other clinicians have already echoed the usefulness of DM type-clustering as a way to optimize treatment approaches. Yet another datadriven analysis conducted by a different team demonstrated that basic clinical features could be equally predictive of DM risk.13
If this pattern is validated in longer follow-up analyses and with other population groups, it could prove a useful prediction tool for long-term DM risk projections. This could facilitate better planning for potentially preventive treatment and perhaps more effective disease management. The prerequisite for its utility is the availability of data for the parameters used, including auto- antibodies, insulin resistance and beta cell function measures.
Other researchers are also exploring this clustering in other geographic areas with different ethnic groups. Further results are expected.
Summary
DM is a highly variable condition in its genesis, its natural progression and its associated disease burdens. The disease process is likely determined by an interplay between a patient’s genes and environment. Genomic studies have helped unlock a better understanding of the molecular processes involved in DM and have updated much of science’s understanding of this disorder. Possible interventions and solutions have also been identified from these studies.
Analyses of the large and newly available data cohorts may use collected information to help organize our knowledge, which may yield significant clinical relevance if followed up over longer time periods and validated across wider population groups.
The portal through which DM is viewed is evolving and the details of its classification framework are under continuous review and revision. The growing information and knowledge bases of this field means our understanding of its disease spectrum is ever sharpening and a personalized diabetes model may eventually be within our grasp.

